Schedule GitLab CI/CD pipelines with Terraform
Brett Weir, February 27, 2023
There are two sides to the problem of continuous integration:
-
On one hand, you need to make sure that new changes don't break existing code. This is a well-known problem, and is usually addressed with a pipeline that runs on every commit.
-
On the other hand, you also need to make sure that old code doesn't break as the world changes around it. Code rot is very real, but not nearly enough attention is paid to it.
If you have only a few projects, and those projects are very active, you'll hardly notice the problem, because when things break, you'll just fix them and move on. But if you have many, or less active, projects, this becomes a very real problem. What will often be the case is that automation will be broken after being left unattended for awhile.
This is why it's important to exercise your automation periodically even if you are not making changes to a repository: to defend against code rot.
In this article, we'll shore up our defenses against code rot by scheduling weekly pipeline runs on all projects, whether we've made commits to them or not.
Sounds easy enough, but this is a great example of a small, simple task that, when attempting to execute at scale, becomes utterly unmanageable:
-
It's easy to go into the GitLab UI and add a pipeline schedule, but doing so for all projects is just too much.
-
How do we keep track of which projects are scheduled to run and when? How do we avoid scheduling too many pipelines at one time?
-
What happens when new projects are created? Will you remember to create a job schedule for them too?
Luckily, in 2023, we have Terraform, which changes this problem from an intractable one, to one that is quite solvable with minimal effort.
Set up the project
You'll need a few things set up before you can get to the main action.
Create a GitLab project
The first thing you'll need to do is a create a GitLab project.
As we go through this tutorial, we'll be adding files to the project's root directory. By the end, your project will look something like this:
data.tf
locals.tf
main.tf
outputs.tf
schedule.html.tpl
terraform.tfCreate a GitLab access token
You'll need to create a GitLab access token that provides Developer level access to all the projects you want to automate.
Create an env.sh file
An API key may be passed to the gitlab provider using the GITLAB_TOKEN
environment variable. For local development, I like to create an env.sh file
and place my credentials in it:
# env.sh
export GITLAB_TOKEN="glpat-XXXXXXXXXXXXXXXXXXXX"This is just a Bash script that I source when I need it. I do this because:
-
I can never remember the
tfvarssyntax, whereas I can remember Bash. -
I dislike adding
-var-file="production.tfvars"to the end of every command. -
This ensures my deployment plays nicely with CI, where all variables will be provided as CI variables.
YMMV. In any case, it's important that this file is ignored. Let's create a
.gitignore file and add the following:
# .gitignore
env.shWhile you're in that file, you can add the standard Terraform ignore patterns as well:
# .gitignore
# ...
.terraform/
*.tfstate*
*.tfvarsSource your
env.sh script so that your token is available going forward:
. env.shYou'll need to source this script at the beginning of every terminal session
where you want to use terraform commands.
Get project data from GitLab
Before we can automate anything, we need to know what's happening on GitLab, like how many projects we have, what their names are, and so on. We'll use Terraform to retrieve this information.
Configure the gitlab provider
We need a way to interact with GitLab via Terraform. In Terraform, the interface to third-party systems is packaged as something called a provider. You can search the Terraform Registry to find publicly available providers.
GitLab maintains their own gitlab
provider. As is
often the case with Terraform providers, it lags behind the upstream API in
terms of features it exposes, but if you're lucky, the coverage is adequate for
your use case, and it improves regularly.
Let's create a file called terraform.tf and add a required_providers
block
declaring the gitlab provider source and version:
# terraform.tf
terraform {
required_providers {
gitlab = {
source = "gitlabhq/gitlab"
version = "~> 15.9.0"
}
}
}When you are happy with your selection, you can initialize the project with
terraform init:
terraform init$ terraform init
Initializing the backend...
Initializing provider plugins...
- Finding gitlabhq/gitlab versions matching "~> 15.9.0"...
- Installing gitlabhq/gitlab v15.9.0...
- Installed gitlabhq/gitlab v15.9.0 (self-signed, key ID 0D47B7AB85F63F65)
...
...
Terraform has been successfully initialized!
...This creates a
.terraform.lock.hcl
file. This file is required. If you don't commit it to your repo, you'll see
messages like this when you try to execute Terraform runs:
$ terraform apply
╷
│ Error: Inconsistent dependency lock file
│
│ The following dependency selections recorded in the lock file are inconsistent with the current configuration:
│ - provider registry.terraform.io/gitlabhq/gitlab: required by this configuration but no version is selected
│
│ To make the initial dependency selections that will initialize the dependency lock file, run:
│ terraform init
╵If you ever need to update your versions or add more providers, you can run
terraform init again with the -upgrade flag:
terraform init -upgradeIf you run a plan right now, you should see "No changes", because no resources
are being created.
terraform plan$ terraform plan
No changes. Your infrastructure matches the configuration.
Terraform has compared your real infrastructure against your configuration and found no differences, so no changes are needed.If you forgot to source your env.sh script, you'll see an error message like
this:
$ terraform apply
╷
│ Error: Invalid provider configuration
│
│ Provider "registry.terraform.io/gitlabhq/gitlab" requires explicit configuration. Add a provider block to the root module and
│ configure the provider's required arguments as described in the provider documentation.
│
╵
╷
│ Error: No GitLab token configured, either use the `token` provider argument or set it as `GITLAB_TOKEN` environment variable
│
│ with provider["registry.terraform.io/gitlabhq/gitlab"],
│ on line 0:
│ (source code not available)
│
╵ In this case, source your env.sh script and try again:
. env.sh
terraform plan$ . env.sh
$ terraform plan
No changes. Your infrastructure matches the configuration.
Terraform has compared your real infrastructure against your configuration and found no differences, so no changes are needed.Now you have the gitlab provider configured.
Get a list of projects
Before we can schedule the pipelines, we need to build a list of all the projects we're going to act on.
Let's create a data.tf file and add the following:
# data.tf
data "gitlab_group" "brettops" {
full_path = "brettops"
}
data "gitlab_projects" "brettops" {
group_id = data.gitlab_group.brettops.id
include_subgroups = true
with_shared = false
}The gitlab_group data
source
makes it much easier to determine the group_id argument. You can skip this if
you know your group ID, but I find that it helps in documenting the intent
of your infrastructure code.
The gitlab_projects data
source
will return all GitLab projects that match its arguments. I've configured it to
return all projects underneath the top-level brettops
group.
Let's run terraform plan to see what we'll get:
terraform plan$ terraform plan
data.gitlab_group.brettops: Reading...
data.gitlab_group.brettops: Read complete after 1s [id=14304106]
data.gitlab_projects.brettops: Reading...
data.gitlab_projects.brettops: Read complete after 1s [id=14304106-4779624565515994815]
No changes. Your infrastructure matches the configuration.
Terraform has compared your real infrastructure against your configuration and found no differences, so no changes are needed.No errors on the data sources, but we can't see any output. Oh, right! We need
to create an output to see anything. Let's create an outputs.tf file and add
the following:
# outputs.tf
output "projects" {
value = data.gitlab_projects.brettops.projects
}Run terraform plan again:
terraform planA huge number of fields are returned by each object on the
data.gitlab_projects.brettops resource:
$ terraform plan
data.gitlab_group.brettops: Read complete after 1s [id=14304106]
data.gitlab_projects.brettops: Reading...
data.gitlab_projects.brettops: Read complete after 1s [id=14304106-4779624565515994815]
Changes to Outputs:
+ projects = [
+ {
+ _links = {
+ "events" = "https://gitlab.com/api/v4/projects/43767043/events"
+ "issues" = "https://gitlab.com/api/v4/projects/43767043/issues"
+ "labels" = "https://gitlab.com/api/v4/projects/43767043/labels"
+ "members" = "https://gitlab.com/api/v4/projects/43767043/members"
+ "merge_requests" = "https://gitlab.com/api/v4/projects/43767043/merge_requests"
+ "repo_branches" = "https://gitlab.com/api/v4/projects/43767043/repository/branches"
+ "self" = "https://gitlab.com/api/v4/projects/43767043"
}
+ allow_merge_on_skipped_pipeline = false
+ analytics_access_level = "disabled"
+ approvals_before_merge = 0
+ archived = false
...
...I won't try to include the whole thing here because it scrolls right off the page (it's 3310 lines long). This is because the resource returns all available information about all returned projects. You can see what this looks like by navigating to the APIv4 URL of a GitLab project.
This will make our plans really noisy if we leave it like this, and we probably
only need a couple of fields. We can create a pruned version of the project list
to make it more manageable by grabbing only fields that we're likely to need for
this deployment. Add a locals.tf file with the following:
# locals.tf
locals {
projects = [
for project in data.gitlab_projects.brettops.projects : {
id = project.id
name = project.path_with_namespace
url = project.web_url
ref = project.default_branch
}
]
}Then we can update the projects output to print the pruned version instead of
the full version:
# outputs.tf
output "projects" {
value = local.projects
}Let's try running terraform plan again:
terraform plan$ terraform plan
data.gitlab_group.brettops: Reading...
data.gitlab_group.brettops: Read complete after 1s [id=14304106]
data.gitlab_projects.brettops: Reading...
data.gitlab_projects.brettops: Read complete after 2s [id=14304106-4779624565515994815]
Changes to Outputs:
+ projects = [
+ {
+ id = 43767043
+ name = "brettops/terraform/deployments/gitlab-pipeline-schedules"
+ ref = "main"
+ url = "https://gitlab.com/brettops/terraform/deployments/gitlab-pipeline-schedules"
},
...
...Pruning the project list reduces the output from 3310 lines to 178 lines, which is profoundly more manageable. I'd much rather see the above output in my CI pipeline than the original output.
Schedule weekly pipeline runs
Now that we have a list of projects to work with, we can work on generating a schedule for them.
I want to distribute these jobs around on a weekly schedule, at random hours. The goal is to prevent too many pipelines from running at once and DDoSing my CI service. This is less of a concern for a hosted CI service, but it's definitely a concern for self-hosting. It also means I won't be looking at a hundred job reports all at once. If there are failures, they'll trickle in instead of overwhelming my inbox.
Configure the random provider
We can use the random_integer
resource
to help with this, which is part of the random
provider.
Let's add it to the terraform.tf file:
# terraform.tf
terraform {
required_providers {
# ...
random = {
source = "hashicorp/random"
version = "~> 3.4.3"
}
}
}terraform init -upgrade$ terraform init -upgrade
Initializing the backend...
Initializing provider plugins...
- Finding gitlabhq/gitlab versions matching "~> 15.9.0"...
- Finding hashicorp/random versions matching "~> 3.4.3"...
- Using previously-installed gitlabhq/gitlab v15.9.0
- Installing hashicorp/random v3.4.3...
- Installed hashicorp/random v3.4.3 (signed by HashiCorp)
...
Terraform has been successfully initialized!
...Reorganize projects as a map
If there is one thing I can't stress enough, it is the importance of organizing
groups of resources as maps instead of lists, and using
for_each
instead of
count
whenever there is more than a single resource.
If you use lists, insertion and removal of elements will often result in Terraform replacing most or all resources instead of only ones that changed. Maps are far safer in almost all cases.
We'll update the projects local in the locals.tf file to produce a map
instead of a list:
# locals.tf
locals {
projects = {
for project in data.gitlab_projects.brettops.projects : project.id => {
id = project.id
name = project.path_with_namespace
url = project.web_url
ref = project.default_branch
}
}
}If you didn't catch that, I changed [] to {} and added project.id =>. Make
sure you pick a stable identifier for your map. In this case, project.id will
not change for the life of the deployment, so it's a great choice.
Running terraform plan again:
terraform plan$ terraform plan
data.gitlab_group.brettops: Reading...
data.gitlab_group.brettops: Read complete after 0s [id=14304106]
data.gitlab_projects.brettops: Reading...
data.gitlab_projects.brettops: Read complete after 2s [id=14304106-4779624565515994815]
Changes to Outputs:
+ projects = {
+ "31710832" = {
+ id = 31710832
+ name = "brettops/pipelines/marp"
+ ref = "main"
+ url = "https://gitlab.com/brettops/pipelines/marp"
}
...
...With those nice IDs out in front, we'll generally have smaller and safer Terraform runs.
Generate random weekly times
Since cron syntax is perennially indecipherable, read the Wiki to try and figure it out, or use a cron editor to spit out the schedule you need:
I figured out that what I need is to pick an hour and weekday to run exactly one
pipeline per week. The following syntax will do the trick, where H is the hour
and D is the day of the week:
0 H * * DWe can pass the projects local to random_integer resources to:
-
Generate hours from
0(12AM) to23(11PM). -
Generate weekdays from
0(Sunday) to6(Saturday).
Let's create a main.tf file and add the following:
# main.tf
resource "random_integer" "hour" {
for_each = local.projects
min = 0
max = 23
}
resource "random_integer" "weekday" {
for_each = local.projects
min = 0
max = 6
}We'll create another local called pipeline_schedules to associate hours and
weekdays with projects. This helps us prevent accidental cycles in the Terraform
graph, and is cleaner than using the values directly. Let's add the following to
the locals.tf file:
# locals.tf
locals {
# ...
pipeline_schedules = {
for project in local.projects : project.id => {
project = project
hour = random_integer.hour[project.id].result
weekday = random_integer.weekday[project.id].result
}
}
}We can add another output for testing purposes:
output "pipeline_schedules" {
value = local.pipeline_schedules
}This is looking pretty good. Let's run terraform plan again:
terraform plan$ terraform plan
data.gitlab_group.brettops: Reading...
data.gitlab_group.brettops: Read complete after 0s [id=14304106]
data.gitlab_projects.brettops: Reading...
data.gitlab_projects.brettops: Read complete after 2s [id=14304106-4779624565515994815]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following
symbols:
+ create
Terraform will perform the following actions:
# random_integer.hour["31710832"] will be created
+ resource "random_integer" "hour" {
+ id = (known after apply)
+ max = 23
+ min = 0
+ result = (known after apply)
}
...
...We now have all the random weekdays and hours we need.
Schedule the pipelines
We have all the pieces in place to schedule our pipelines:
-
Access to GitLab from Terraform,
-
A list of projects we want to automate, and
-
Times for our pipelines to run.
The final step here is to put it all together and create an actual pipeline
schedule using the
gitlab_pipeline_schedule
resource. We need to tell it what project to use, what branch to run, the cron
schedule, a description to tell people what this job is for, and we'll use
for_each to generate one pipeline schedule per project in our list. Let's do
so by adding the following to the main.tf file:
# main.tf
# ...
resource "gitlab_pipeline_schedule" "brettops" {
for_each = local.pipeline_schedules
project = each.key
ref = each.value.project.ref
cron = "0 ${each.value.hour} * * ${each.value.weekday}"
description = "Terraform-managed weekly run to exercise pipelines"
}Instead of running terraform plan, we'll run terraform apply, because we're
at a point where the Terraform run is likely to complete successfully:
terraform apply$ terraform apply
data.gitlab_group.brettops: Reading...
data.gitlab_group.brettops: Read complete after 1s [id=14304106]
data.gitlab_projects.brettops: Reading...
data.gitlab_projects.brettops: Read complete after 1s [id=14304106-4779624565515994815]
Terraform used the selected providers to generate the following execution
plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# gitlab_pipeline_schedule.brettops["31710832"] will be created
+ resource "gitlab_pipeline_schedule" "brettops" {
+ active = true
+ cron = (known after apply)
+ cron_timezone = "UTC"
+ description = "Terraform-managed weekly run to exercise pipelines"
+ id = (known after apply)
+ project = "31710832"
+ ref = "main"
}
...
...
...
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value:I'm feeling pretty good about this. Let's do it!
...
Enter a value: yes
random_integer.weekday["32603100"]: Creating...
random_integer.weekday["32284482"]: Creating...
random_integer.weekday["31712416"]: Creating...
...
...
...
Apply complete! Resources: 81 added, 0 changed, 0 destroyed.
...Freaking awesome. Now every project in the entire company runs on a weekly
schedule, and at different times to prevent a thundering herd
problem from emerging.
You can now visit any brettops
project
and see a Terraform-managed schedule:
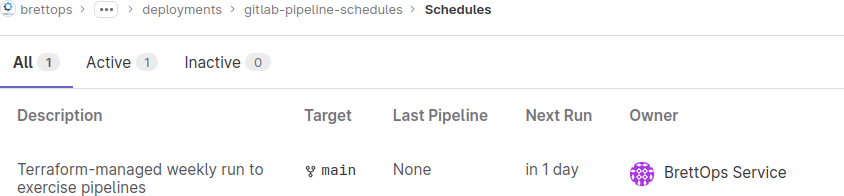
Make a pipeline schedule page
It would be very helpful to see when things are actually scheduled to run. Terraform has extensive support for templating, and since templating is 99% of what static site generators do, Terraform is actually not a terrible way to generate a small static site as part of a deployment process. This is awesome for when you you've just generated a bunch of resources and want to document what exists for your users.
To that end, we'll use the local_file
resource
from the local
provider. This
resource allows us to write a file to the local filesystem from Terraform.
First, we need to add it to the provider list in the terraform.tf file:
# terraform.tf
terraform {
required_providers {
# ...
local = {
source = "hashicorp/local"
version = "~> 2.3.0"
}
}
}terraform init -upgrade$ terraform init -upgrade
Initializing the backend...
Initializing provider plugins...
- Finding hashicorp/random versions matching "~> 3.4.3"...
- Finding hashicorp/local versions matching "~> 2.3.0"...
- Finding gitlabhq/gitlab versions matching "~> 15.9.0"...
- Using previously-installed hashicorp/random v3.4.3
- Installing hashicorp/local v2.3.0...
- Installed hashicorp/local v2.3.0 (signed by HashiCorp)
- Using previously-installed gitlabhq/gitlab v15.9.0
...
Terraform has been successfully initialized!
...Next, we'll need to do is organize the schedule data into a format that is amenable to templating. We'll arrange it by row and column using hour and weekday, instead of having a flat list of projects:
# locals.tf
locals {
# ...
schedule_page = [
for hour in range(24) : {
hour = format("%02s:00", hour)
weekdays = [
for weekday in range(7) : [
for schedule in local.pipeline_schedules : {
name = schedule.project.name
url = schedule.project.url
} if schedule.hour == hour && schedule.weekday == weekday
]
]
}
]
}The next thing we need is a template. In its simplest form, we just need to
split out an HTML table. I added some conditionals and ~ to make the rendered
output prettier, but it's just a table:
<!-- schedule.html.tpl -->
<h1>Pipeline Schedule</h1>
<table>
<tr>
<td>Sunday</td>
<td>Monday</td>
<td>Tuesday</td>
<td>Wednesday</td>
<td>Thursday</td>
<td>Friday</td>
<td>Saturday</td>
</tr>
%{~ for hour in schedule ~}
<tr>
<td>${ hour.hour }</td>
%{~ for weekday in hour.weekdays ~}
<td>
%{~ if length(weekday) > 0 }
<ul>
%{~ for project in weekday ~}
<li><a href="${ project.url }">${ project.name }</a></li>
%{~ endfor ~}
</ul>
%{ endif ~}
</td>
%{~ endfor ~}
</tr>
%{~ endfor ~}
</table>And finally, we'll use the built-in templatefile
function
to read the template into the local_file resource, which will write out the
finished template to public/index.html.
# main.tf
resource "local_file" "schedule_page" {
content = templatefile("${path.module}/schedule.html.tpl", {
schedule = local.schedule_page
})
filename = "${path.module}/public/index.html"
file_permission = "0644"
}We should add the public/ directory to our .gitignore, since we don't want
to accidentally commit our file outputs:
# .gitignore
# ...
public/Let's apply!
terraform apply$ terraform apply
data.gitlab_group.brettops: Reading...
data.gitlab_group.brettops: Read complete after 0s [id=14304106]
data.gitlab_projects.brettops: Reading...
data.gitlab_projects.brettops: Read complete after 2s [id=14304106-4779624565515994815]
...
...
...
Terraform will perform the following actions:
# local_file.schedule_page will be created
+ resource "local_file" "schedule_page" {
+ content = <<-EOT
<h1>Pipeline Schedule</h1>
<table>
<tr>
<td>Sunday</td>
...
...
...
Plan: 1 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value:
It's looking good! Let's say "yes".
...
Enter a value: yes
local_file.schedule_page: Creating...
local_file.schedule_page: Creation complete after 0s [id=4dc6b18368d7a6dcda8114db4ab37a7683af780f]
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
...
...You can view the end result in your browser:
firefox public/index.htmlIf you're not following along locally, I've also uploaded the result here.
Style the site (bonus)
Not bad for the the first run of our "Terraform Static Site Generator". It's pretty barebones though.
You can spice up the page by just throwing the Bootstrap beginner tutorial at it, turning on some table formatting, and re-applying:
<!-- schedule.html.tpl -->
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<title>Pipeline Schedule</title>
<link
href="https://cdn.jsdelivr.net/npm/[email protected]/dist/css/bootstrap.min.css"
rel="stylesheet"
integrity="sha384-GLhlTQ8iRABdZLl6O3oVMWSktQOp6b7In1Zl3/Jr59b6EGGoI1aFkw7cmDA6j6gD"
crossorigin="anonymous"
/>
</head>
<body>
<h1>Pipeline Schedule</h1>
<table class="table">
<tr>
<th>Sunday</th>
<th>Monday</th>
<th>Tuesday</th>
<th>Wednesday</th>
<th>Thursday</th>
<th>Friday</th>
<th>Saturday</th>
</tr>
%{~ for hour in schedule ~}
<tr>
<th>${ hour.hour }</th>
%{~ for weekday in hour.weekdays ~}
<td>
%{~ if length(weekday) > 0 }
<ul>
%{~ for project in weekday ~}
<li><a href="${ project.url }">${ project.name }</a></li>
%{~ endfor ~}
</ul>
%{ endif ~}
</td>
%{~ endfor ~}
</tr>
%{~ endfor ~}
</table>
<script
src="https://cdn.jsdelivr.net/npm/[email protected]/dist/js/bootstrap.bundle.min.js"
integrity="sha384-w76AqPfDkMBDXo30jS1Sgez6pr3x5MlQ1ZAGC+nuZB+EYdgRZgiwxhTBTkF7CXvN"
crossorigin="anonymous"
></script>
</body>
</html>terraform applyThe output here is so long that it's not worth reproducing in full, but say yes:
...
Enter a value: yes
local_file.schedule_page: Destroying... [id=4dc6b18368d7a6dcda8114db4ab37a7683af780f]
local_file.schedule_page: Destruction complete after 0s
local_file.schedule_page: Creating...
local_file.schedule_page: Creation complete after 0s [id=a579416dcf48c80553db7ebba9a744d272ca0ad9]
Apply complete! Resources: 1 added, 0 changed, 1 destroyed.
...Check it out now (also uploaded here):
firefox public/index.htmlSo pretty!
Move the deployment to GitLab
At this point, we should move to hosting this on GitLab so that it becomes a permanent piece of automation.
Destroy all resources
First, let's destroy all the resources we've created so far! 💀
Re-generating the resources we've made is a lot less labor-intensive than trying to migrate the state, and Terraform is useful for things like this:
terraform destroy$ terraform destroy
...
...
...
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
...
random_integer.hour["43630020"]: Destruction complete after 0s
random_integer.weekday["37955984"]: Destruction complete after 0s
random_integer.hour["33446385"]: Destruction complete after 0s
Destroy complete! Resources: 82 destroyed.It's fine—it's just 82 resources!
Configure the state backend
We need to configure the state backend to use with
GitLab.
We can do this by adding backend "http" {} to the terraform.tf file:
# terraform.tf
terraform {
backend "http" {}
# ...
}There's additional state configuration that the terraform pipeline will handle
automatically, so there's nothing else needed here.
Add a CI file
Next, we'll add the BrettOps terraform
pipeline so that we can start
running deploys from within GitLab.
BrettOps only has one GitLab group, so we only need one deployment pipeline.
We'll use the default terraform
pipeline.
Let's create a .gitlab-ci.yml file and add the following:
# .gitlab-ci.yml
include:
- project: brettops/pipelines/terraform
file: include.ymlThis provides a basic workflow for deploying the root project directory with Terraform.
We also want to add the pages
pipeline:
# .gitlab-ci.yml
include:
# ...
- project: brettops/pipelines/pages
file: include.ymlThis will make it easy to turn on GitLab Pages without needing to modify our other pipelines for it.
There's one more tweak to make. The terraform-apply job in the terraform
pipeline will be the job that creates the pipeline schedule page. We want to
publish that page with GitLab Pages, so we need to save the public directory
as an artifact. This is also why we created the page at public/index.html.
We'll also move terraform-apply to an earlier stage so that the page exists
before the pages job runs:
# .gitlab-ci.yml
terraform-apply:
stage: build
artifacts:
paths:
- public/Oh, and don't forget to add the GitLab token to your project CI variables!
Publish!
Wrap it all up and you should be ready to commit and publish:
git add .
git commit -m "Initial commit"
git pushVisit your project CI pipelines
page
to check the progress, and when the terraform-plan job is complete, you can
manually trigger the terraform-apply job. When complete, all of your projects
will have scheduled pipelines, and your pipeline schedule will be published to
GitLab Pages for all to see.
Conclusion
It's hard to overstate how much time was saved by using Terraform to accomplish this task, and how Terraform, in this way, acted as a key enabler of an activity that would otherwise likely not take place at all. Look at all the benefits we'll get going forward:
-
Projects that are not under active development will now see more regular testing than they would otherwise, which will defend against surprises just when you need to make a hotfix.
-
Major unexpected CI platform changes will now be easier to detect with all supported jobs running on a regular basis.
-
Our pipelines will be distributed throughout the week so that there's never one time when the CI infrastructure gets hammered all at once.
-
Onboarding and offboarding projects is easy! All you have to do is re-run the pipeline and Terraform will do the right thing dynamically and by design.
-
This project will even schedule itself to run weekly, which will ensure new projects are onboarded automatically. 😵
My executive summary for this week is: dang!