Deploy a Kubernetes cluster on DigitalOcean with Terraform and GitLab
Brett Weir, June 12, 2023
This article will talk about how to build a Kubernetes cluster that's less work to operate, self-healing, and, in general, awesome.
Our cluster will:
-
Run on DigitalOcean, using all the nice DigitalOcean stuff.
-
Be managed by a Git repository from day one.
-
Be automated by a GitLab CI/CD pipeline.
For this article, we'll rely on GitLab automation instead of configuring Terraform for local development. To test your pipeline, just commit!
Why DigitalOcean
DigitalOcean is just. So. Easy to use. When compared to AWS, Azure, or GCloud, there is no comparison. The experience is fresh and inviting and feels like a toolkit you want to use, rather than one you have to use.
The downside to DigitalOcean is that their cloud capabilities are pretty bare-bones. If you want GPUs or managed Kafka or autoscaling Postgres or cluster OIDC, you'll have to look elsewhere.
However, if your needs are less complex, you want something that doesn't consume your life, and you like actually good documentation, then DigitalOcean is your jam.
DigitalOcean maintains an awesome digitalocean/digitalocean Terraform
provider,
which makes it very easy to administer your entire DigitalOcean infrastructure
without leaving GitLab.
Prerequisites
-
A GitLab account. We use GitLab to store our project and for the GitLab-managed Terraform state.
-
A DigitalOcean account. This is where we will deploy our Kubernetes cluster.
Set up a deployment project
Create a GitLab project
The first thing you'll need to do is a create a GitLab project.
Using GitLab is important because we're using GitLab-managed Terraform state to provide our delivery infrastructure.
Create a DigitalOcean API token
We can supply an API token to the digitalocean/digitalocean Terraform provider
using the
DIGITALOCEAN_TOKEN
environment variable. To do that, you'll need an API token.
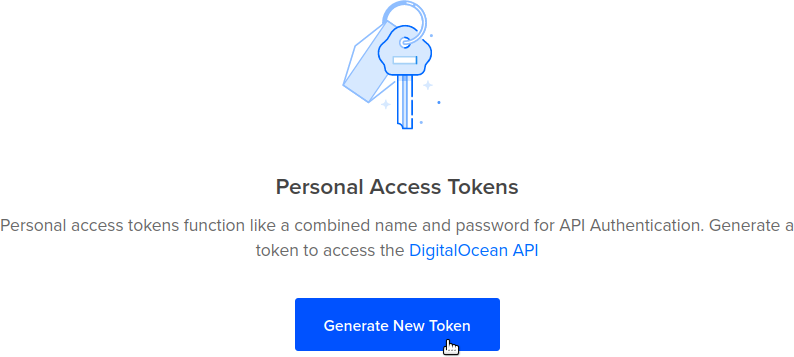
Once you have a DigitalOcean account, visit the API Tokens page of DigitalOcean and click the Generate New Token button:
You'll next see the new access token pop-up:
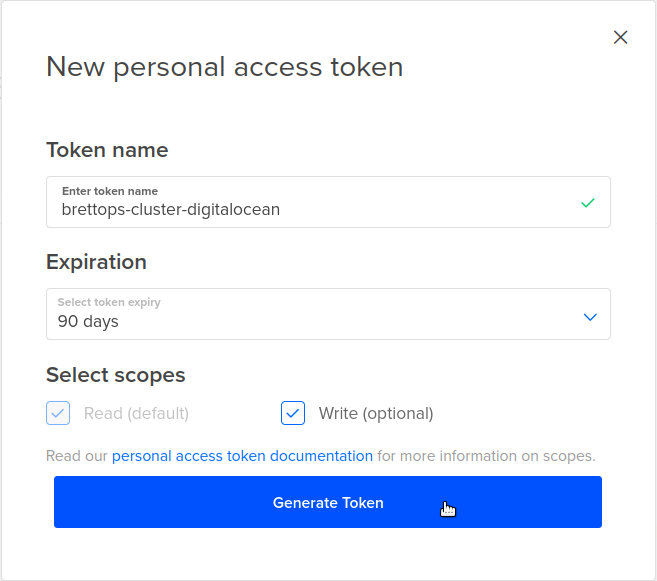
You can provide the following values:
-
Token name - Give your token a good name; one that actually describes what it's for. You'll thank yourself later.
-
Expiration - The default expiration is fine. You'll want to rotate these credentials periodically.
-
Select scopes - Ensure that Write (optional) is checked, so that this key can be used to create resources with Terraform.
When you're done configuring, click Generate Token, which will close the dialog box. For the next part, we'll need the newly created API token, so go ahead and copy the token now:
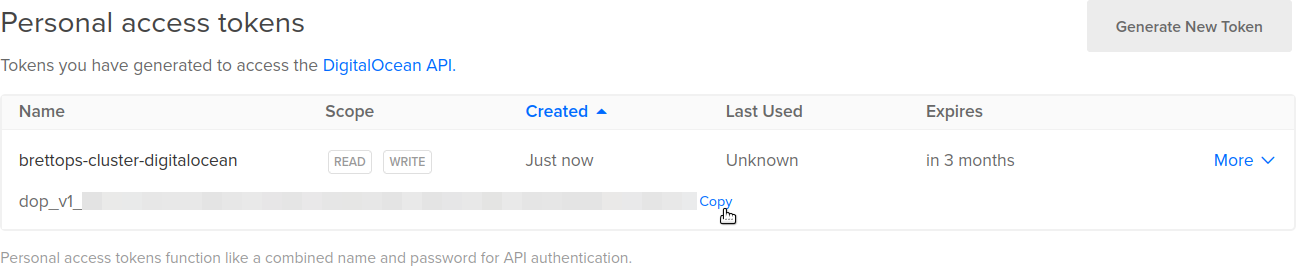
Add as CI/CD variable
With the API token copied, navigate to your GitLab project's CI/CD Settings page, then click Expand to expand the Variables section:
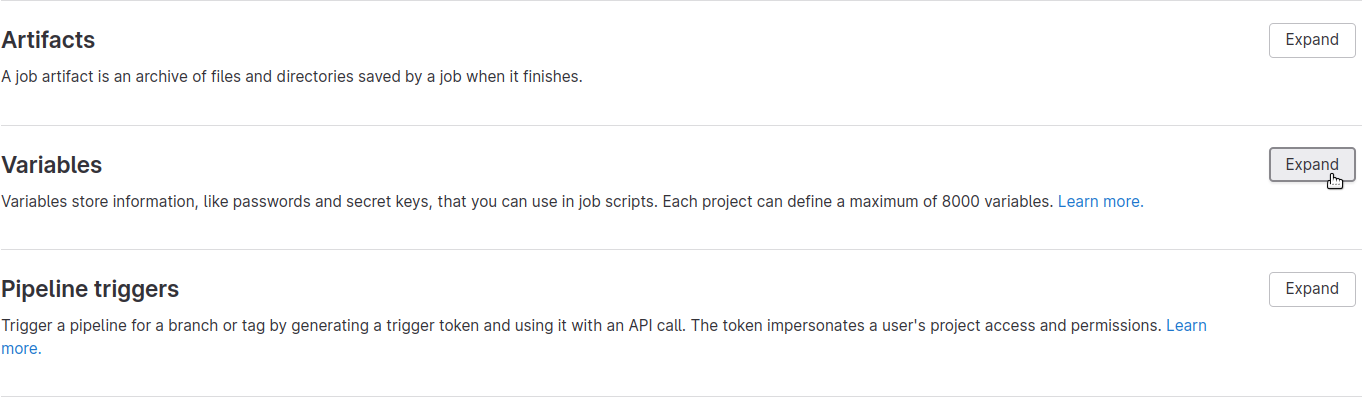
Then click Add variable:
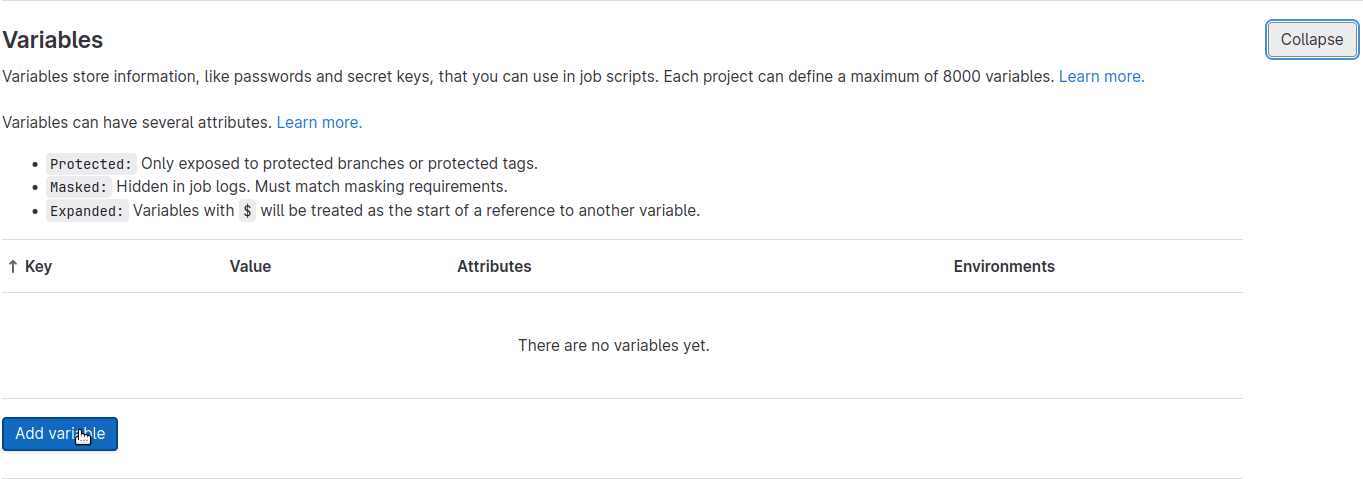
A dialog box will pop up for us to supply a CI/CD variable. It should be configured as follows:
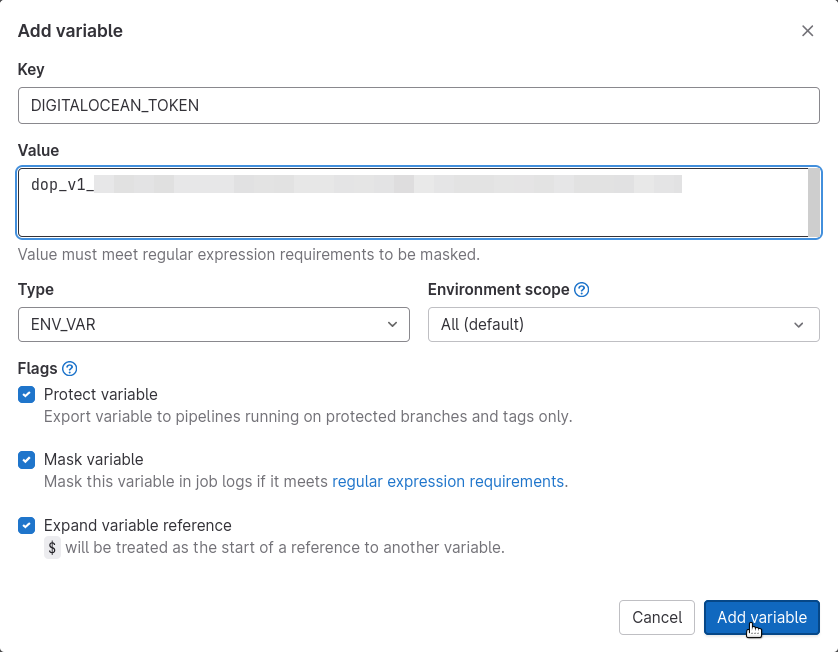
-
Key:
DIGITALOCEAN_TOKEN -
Value: paste the copied DigitalOcean API token here
-
Protect variable: checked
-
Mask variable: checked
-
Expand variable reference: checked
Then, hit Add variable. The dialog box will close, and you'll see your new variable appear on the page:
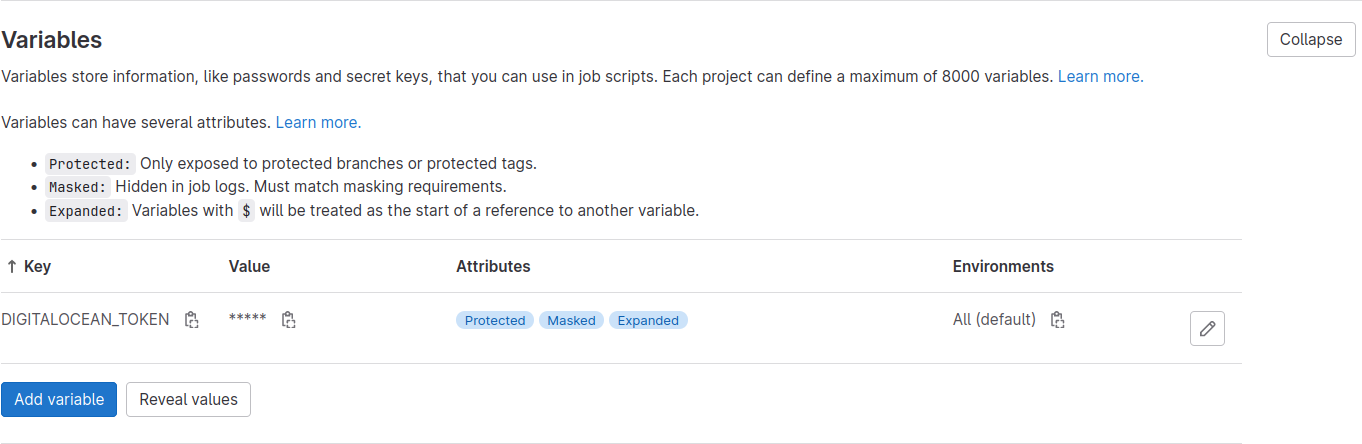
Now we'll start laying out the scaffolding for our project.
Configure for dual deployment
To continuously deliver our Kubernetes cluster, we're going to use the "dual
deployment" variant of the BrettOps terraform
pipeline.
What is dual deployment?
This pipeline provides matched production and staging environments for the single Terraform configuration. Changes to the deployment are first immediately applied to the staging environment, then a manual gate confirms their application to production. That way, you can validate nearly the exact sequence of changes to make to your production cluster before ever touching the production environment.
This makes deployments much less scary.
In addition, the dual deployment pipeline is designed so that the deployments can diverge when they absolutely need to, even in arbitrary ways, yet still share the same code everywhere else. It's kind of like having two projects in one.
Project scaffolding
A dual deployment project generally looks something like this:
deploy/
production/
.terraform.lock.hcl
main.tf
terraform.tf
staging/
.terraform.lock.hcl
main.tf
terraform.tf
.gitignore
.gitlab-ci.yml
data.tf
locals.tf
main.tf
terraform.tf
variables.tfLet's break it down:
-
The project directory contains Terraform configuration that is shared between all deployments.
-
A
deploydirectory contains specific environments, with each directory representing the actual root folder of the Terraform deployment. -
The root directory is used as a module from the environment directories so that operators can code in full HCL if variation is necessary between staging and production environments.
My Terraform projects have a lot of boilerplate, which I won't apologize for. It feels top-heavy when the repo is almost empty, but makes a lot more sense as the project grows in complexity.
Add deploy/<env>/main.tf
In this setup, the deploy directories are the Terraform root directories and use the project root directory as a module:
# deploy/production/main.tf
module "root" {
source = "../.."
environment = "production"
}# deploy/staging/main.tf
module "root" {
source = "../.."
environment = "staging"
}Add deploy/<env>/terraform.tf
Both Terraform working directories are configured to use GitLab-managed Terraform state:
# deploy/production/terraform.tf
terraform {
backend "http" {
}
}# deploy/staging/terraform.tf
terraform {
backend "http" {
}
}Add deploy/<env>/.terraform.lock.hcl
Each deploy directory is the root of its own effective Terraform project. Terraform plans are run from the respective deploy directories, and can have their own divergent provider versions. This is tedious to maintain, but allows provider versions to be managed independently, which comes in handy at times.
We can't create this file until we've built out more of the project, but we'll come back to this.
Add .gitignore
Obligatory Terraform ignores:
.terraform/
*.tfstate*
*.tfvarsAdd .gitlab-ci.yml
The GitLab CI file for this project implements the "dual deployment" variant of
the terraform pipeline:
stages:
- test
- build
- deploy
include:
- project: brettops/pipelines/terraform
file: dual.ymlAdd locals.tf
I like to include values for deployment and environment to help keep
deployments organized:
# locals.tf
locals {
deployment = "brettops"
environment = var.environment
}You can combine these base values into a unique deployment name:
# locals.tf
locals {
# ...
name = "${local.environment}-${local.deployment}"
}When complete, it'll look something like this:
# locals.tf
locals {
deployment = "brettops"
environment = var.environment
name = "${local.environment}-${local.deployment}"
}Deploy changes
We're going to lean on GitLab here to deploy our infrastructure for us, instead of configuring Terraform locally. To test our changes, we can simply commit them. We've set everything up so that our commits will trigger CI/CD pipelines to provision staging and production environments for us. If we need to, we can make changes to the infrastructure by making further commits.
Anyway, let's make our initial commit:
git add .
git commit -m "Initial commit"
git pushIf you visit your GitLab repository and navigate to the Pipelines page, you'll see that a pipeline has been triggered. The staging environment will have started (or more likely, already finished), and the production environment will be waiting for your approval:
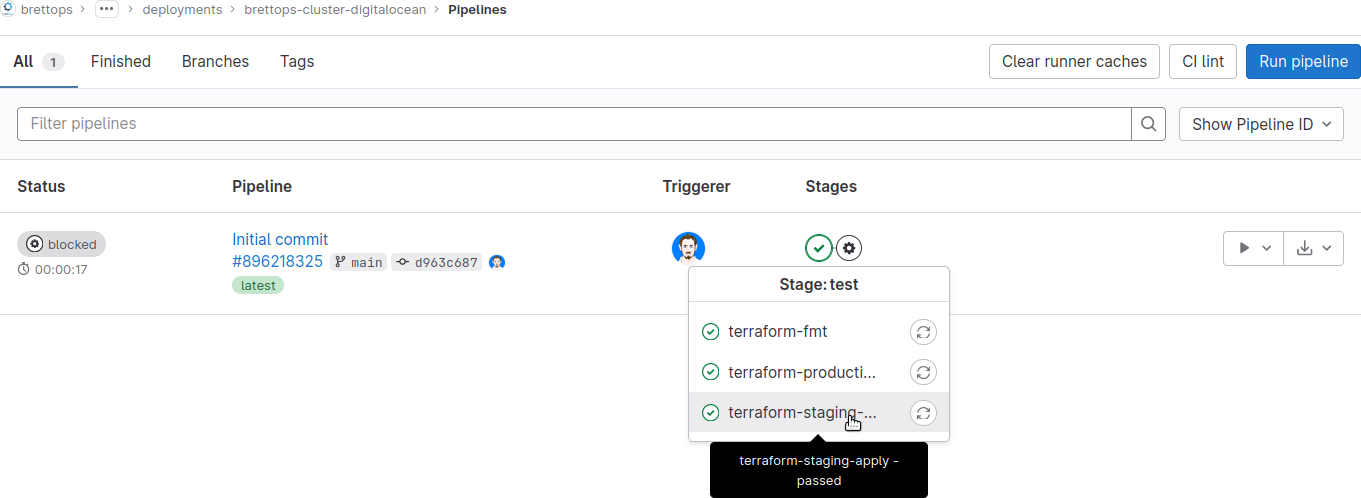
You can review your pipeline logs to see what exactly Terraform did, and if you're feeling good about the results, you can apply to production. However, nothing is actually deployed by the project yet. Running the production pipeline mostly tests that we set everything up correctly.
To apply to production, click the black gear icon for your deployment pipeline,
and then click the Play button next to the terraform-production-apply job:
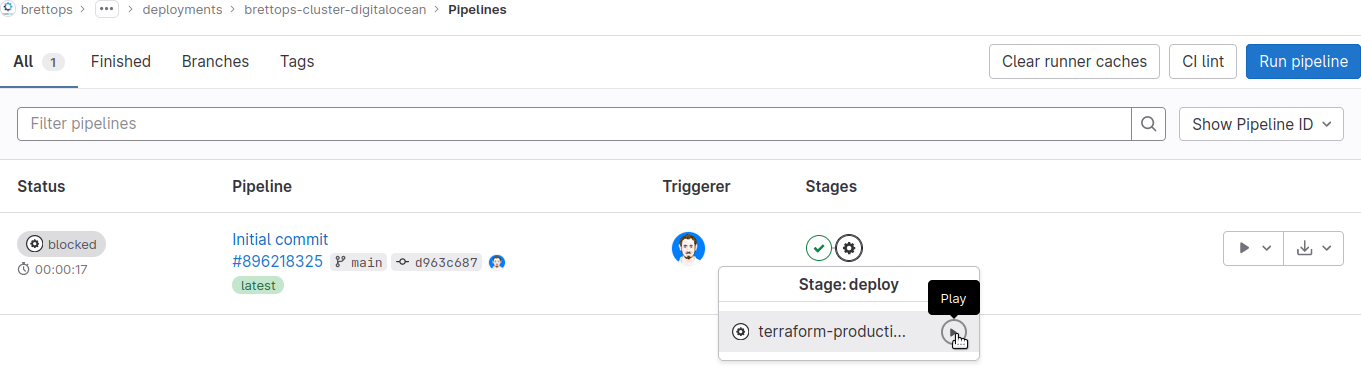
terraform-production-apply pipeline job to deploy to production.We've successfully deployed nothing to both staging and production. Hooray!
Now to add some real stuff to our deployment.
Add VPCs
As part of our cluster deployment, we'll first deploy our own Virtual Private Cloud (VPC) resources. This will allow us to put each cluster on its own network and prevent them from interacting with each other, which is good for security and resilience.
DigitalOcean has a digitalocean_vpc
resource
that we can use to deploy VPCs into our account.
Configure the DigitalOcean provider
Add a terraform.tf file and add the DigitalOcean Terraform provider:
# terraform.tf
terraform {
required_providers {
digitalocean = {
source = "digitalocean/digitalocean"
version = "~> 2.22"
}
}
required_version = ">= 1.0"
}Now it's possible to initialize the providers. We'll need to do both:
terraform -chdir=deploy/staging/ init -upgrade -backend=false
terraform -chdir=deploy/production/ init -upgrade -backend=false-
Use
-upgradeto pin to the latest provider version that matches our version constraint. -
Use
-backend=falseto ignore the state backend and just lock the providers.
This creates the .terraform.lock.hcl files we mentioned earlier.
Define a region
Many DigitalOcean resources correspond to real things that are deployed in real places. For these resources, you'll need to tell DigitalOcean what data center you'd like to use, which is done by specifying a region.
We'll define our region as a local value because we'll need to reuse it often:
# locals.tf
locals {
# ...
region = "sfo3"
}Configure IP address ranges
When the VPC is created, it will need a unique IP address range, as DigitalOcean requires it. Pass it in as a variable:
# locals.tf
locals {
# ...
vpc_ip_range = var.vpc_ip_range
}# variables.tf
# ...
variable "vpc_ip_range" {
type = string
}When complete, it'll look something like this:
# locals.tf
locals {
deployment = "brettops"
environment = var.environment
name = "${local.environment}-${local.deployment}"
region = "sfo3"
vpc_ip_range = var.vpc_ip_range
}The IP address range I chose is arbitrary. I wanted a lot of IP addresses so
that I'd never run out, and I found an example in the
documentation
that used a 10.x.x.x/16 address:
# deploy/production/main.tf
module "root" {
# ...
vpc_ip_range = "10.10.0.0/16"
}# deploy/staging/main.tf
module "root" {
# ...
vpc_ip_range = "10.11.0.0/16"
}Finally, create the VPC resource. Create and add the following to main.tf:
# main.tf
resource "digitalocean_vpc" "cluster" {
name = local.name
region = local.region
ip_range = local.vpc_ip_range
}Deploy changes
Like we did previously, commit and push the changes we just made:
git add .
git commit -m "Add VPCs"
git pushThen wait for the staging pipeline to complete like before. When it completes, a
staging-brettops VPC will now exist in DigitalOcean, and you can check it out
on the VPC Networks page:
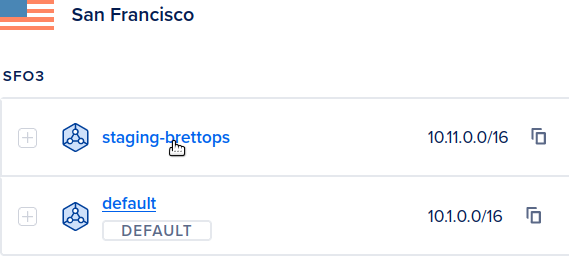
staging-brettops> VPC now exists in DigitalOcean.Like before, if you're feeling good about the deployment, run the manual
production pipeline job to deploy to production. You'll see a new
production-brettops VPC alongside the staging-brettops VPC from before:
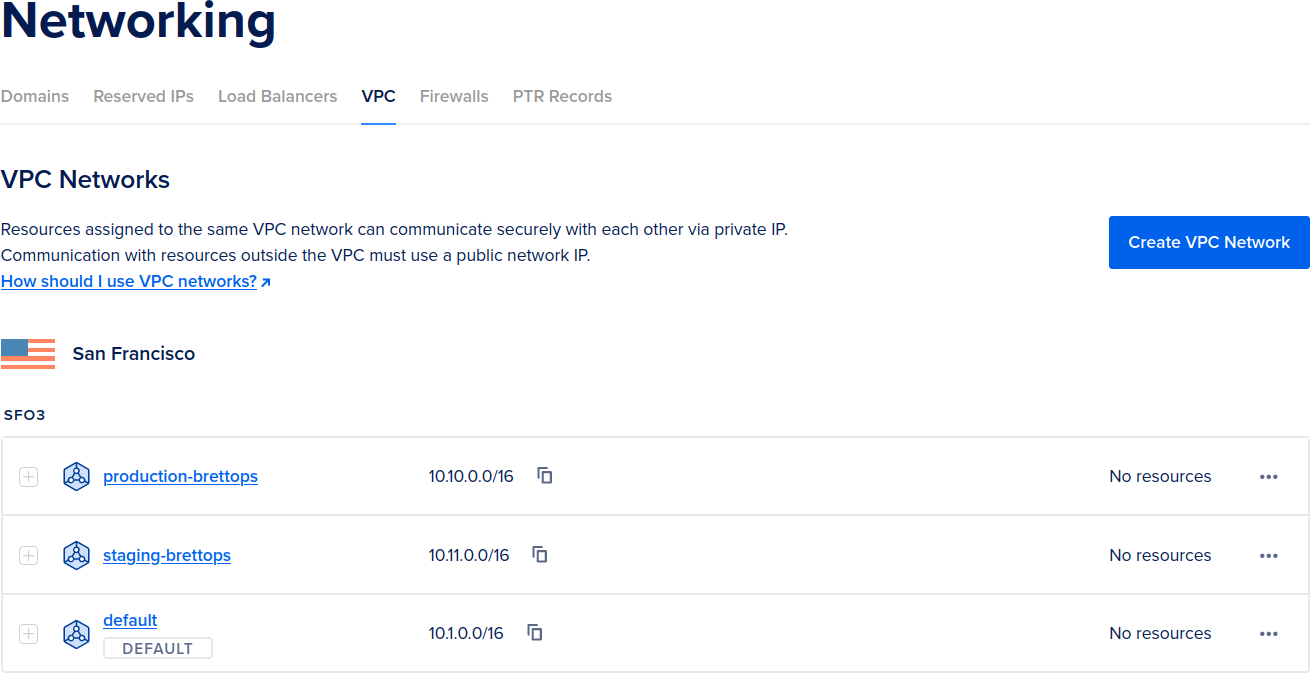
production-brettops VPC appears alongside the `staging-brettops` VPC.With our VPCs up and running, we can get to work on deploying the clusters themselves.
Add the clusters
DigitalOcean makes it incredibly easy to deploy a Kubernetes cluster. With some cloud providers, this process may require configuring dozens of resources for a minimal cluster, but with DigitalOcean, it only requires one or two. Happy sigh.
Get the latest Kubernetes version
Create and add the following to a data.tf file. This will allow you to query
for the latest Kubernetes cluster version supported by DigitalOcean.
# data.tf
data "digitalocean_kubernetes_versions" "cluster" {}This query will re-run every time the deployment pipeline runs, so using this data source will also automatically upgrade your clusters when there is a new minor Kubernetes version out.
Add the cluster resource
DigitalOcean has the digitalocean_kubernetes_cluster
resource,
which is fairly straightforward to set up:
# main.tf
# ...
resource "digitalocean_kubernetes_cluster" "cluster" {
auto_upgrade = true
name = local.name
region = local.region
surge_upgrade = true
version = data.digitalocean_kubernetes_versions.cluster.latest_version
vpc_uuid = digitalocean_vpc.cluster.id
node_pool {
auto_scale = true
name = "${local.name}-default"
max_nodes = 5
min_nodes = 1
size = "s-2vcpu-2gb"
}
}Let's break this down:
-
nameandregionare the cluster name and deployment region. -
vpc_uuidshould be the ID of the VPC we deployed. -
versionwill be queried automatically from the data source. -
auto_upgradeandsurge_upgradetell DigitalOcean to upgrade your cluster when new minor versions are available, as well as increase cluster capacity so that you won't have an outage during an upgrade. These should most always be set totrue. -
For the
node_poolblock, we have it configured to scale up automatically, with the size set to a small and cheap machine.
name, region, and vpc_uuid cannot be changed without re-deploying the
cluster. node_pool.name and node_pool.size can be changed, but it's not
currently possible to do without doing manual state changes. Choose values
wisely.
Deploy changes
Just like before, commit and push the changes:
git add .
git commit -m "Add cluster"
git pushHowever, this job will take a bit longer than previously, about five minutes. This feels like an eternity, but it's amazing that getting a fully-functional cluster only takes five minutes of waiting:
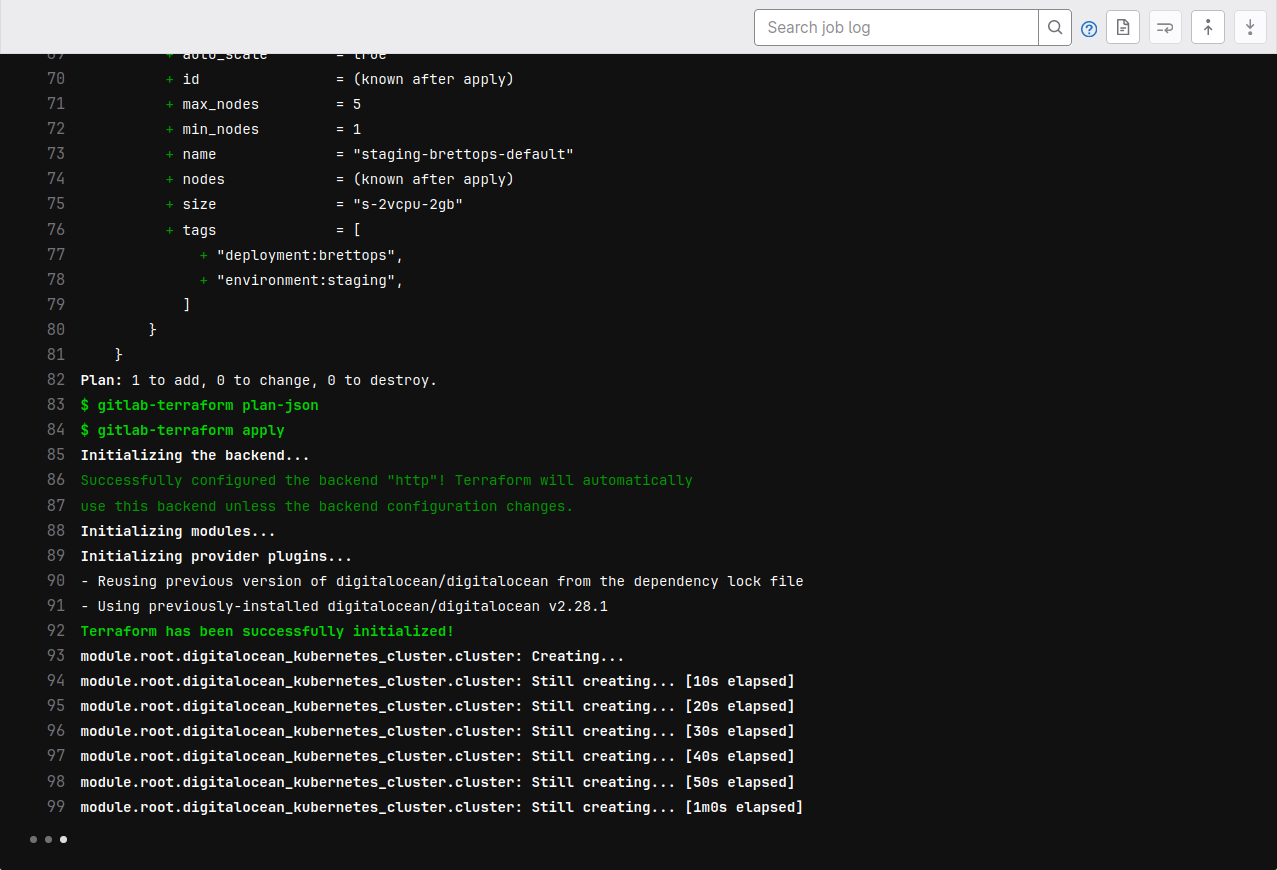
Eventually, it will finish and you'll have yourself a shiny new staging cluster. Check its status on the DigitalOcean Kubernetes Clusters page:

Once you're confident about staging, approve for production, and you're good to go!
Conclusion
This is a cluster deployment that is easy to manage, safe to operate, and documented and automated from day one.
Instead of figuring out how to back up clusters, or biting your teeth wondering if your change is going to break production, you can just have at it, try before you buy, and prevent bad changes from making it to production in the first place. You can even test changes in staging while waiting for the previous production pipeline to complete. How awesome is that!
This frees you up for the real reason you wanted to use Kubernetes in the first place: deploy lots of apps together, pool resources, and provide a consistent API for your developers to build on.
Job's done, let's make some stuff! Until next time!